
Measuring Accuracy in Prediction Markets and Opinion Poll/Pools
Introduction
One of the first and most important questions we get from clients, forecasters, and consumers of our data is: “How accurate are these forecasts?”. In order to answer this question, we have utilized and built upon a widely accepted proper scoring rule, i.e. a way to measure accuracy for a probabilistic forecast. In addition to utilizing these mathematical formulas, we also provide a variety of leaderboards and several display options which allow forecasters and stakeholders to consume these scores in easily understandable formats, making it easy to recognize accurate forecasts and forecasters without having to understand scoring theory.
Scoring Overview
The basis for our measures of accuracy, both for the consensus forecast of a questions and forecasts of individual users, is derived from the proper scoring rule called Brier Scoring. Brier Scoring was first proposed by Glenn Brier in 1950 as a method for measuring the accuracy of weather forecasts:
http://docs.lib.noaa.gov/rescue/mwr/078/mwr-078-01-0001.pdf
We use the following formula to calculate Brier scores:
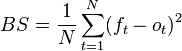
where t is a period of time (usually a day),
N is the number of periods (days) that a question is
active, ft is the
forecast at at time t,
and ot is the outcome of the question: 1 (or 100%) if the
outcome being forecasted occurs, 0 (or 0%) if it doesn’t.
For a given question or user, we generate a Brier score between 0 and 2:
|
Brier Score |
Interpretation |
|
0 |
Perfect forecast at all time periods |
|
2 |
Worst possible forecast at all time periods |
Scoring Question Accuracy
Scores are generated when a question is resolved (the outcome is known) and are based on the consensus probabilities or prices throughout the life of the question. The score is determined by calculating a Brier score score using the consensus forecasts at the end of each time period, usually daily, that the question was active and then finding the average of those component scores.
Consensus Forecast
A pure opinion pool elicits probability estimates from forecasters. The consensus forecast for an outcome is based on some averaging methodology: The mean, median, or a more complex methodology.
A pure prediction market elicits trades from forecasters, and uses a scoring rule to determine a price for the outcome. The consensus forecast for an outcome is that price.
The hybrid prediction market augments the trading by eliciting a probability estimate in addition to the trade. We are thus able to construct a consensus probability based upon the probability estimate that will run alongside the price. For the purposes of scoring, we can use either or both the price and consensus probability.
Score Calculation
Question Structure Refresher
All questions have more than one possible outcome: Yes or No; A, B, or C; 1, 2, 3, or 4 or more; etc. We refer to these potential outcomes as answers. The sum of the probabilities of each answer always sums to 1 (100%); There is a 100% chance that one of the possible outcomes will occur. If the question does not fit this requirement, it is not a forecastable question.
The Calculation
We calculate a Brier score for each answer and sum them to arrive at a score for the question. We calculate a score for the question each time-period, using the consensus probability or price at the end of the time-period, and average those component scores together to arrive at a score for the question.
Note on Binary (One Answer) Questions
A Binary question is one where users make forecasts on only one answer. These questions usually come in the form of “Will X occur?” and participants forecast on a single answer representing “Yes”. A forecast of 100% represents 100% probability that X will occur. A forecast of 0% represent 0% probability that X will occur. Implicitly, 100% that X will occur is 0% that X will not occur. Thus, there is an implicit “No” answer whose probability will always be inverse of the explicit “Yes”. When calculating the score for these questions, we simply score the implicit “No” answer in addition to the “Yes” to arrive at a Brier score between 0 and 2.
Example 1
- A binary (“Will X occur?”) question is initialized with a probability of 50%
- On day 2 forecasts are made that move the consensus to 65%
- On day 3, forecasts are made that move the consensus back down to 50%
- On day 4, forecasts are made that move the consensus to down further to 35%
- On day 5, forecasts are made that move the consensus to back up to 50%
- On day 6, forecasts are made that move the consensus down 35%
- The market resolves as true (100%) on day 6
The Brier score for each day is equal to (f - 1)^2. For day 1, the Brier score is (0.5 - 1)^2 = 0.25, and for day 2, the Brier score is (0.6457 - 1)^2 = 0.1255. The Brier scores for each of the thirty days are:
Day 1 Brier score: (0.5 - 1)^2 + (0.5 - 0)^2 = 0.5
Day 2 Brier score: (0.65 - 1)^2 + (0.35 - 0)^2 = 0.25
Day 3 Brier score: (0.5 - 1)^2 + (0.5 - 0)^2 = 0.5
Day 4 Brier score: (0.35 - 1)^2 + (0.65 - 0)^2 = 0.85
Day 5 Brier score: (0.5 - 1)^2 + (0.5 - 0)^2 = 0.5
Day 6 Brier score: (0.35 - 1)^2 + (0.65 - 0)^2 = 0.85
The Accuracy score for this question, which is the average of these daily Brier scores, is 0.57.
Example 2
- A question initialized with 5 possible answers, each with a probability of 20%
- On day 2, forecasts are made that change the consensus probability of Answer 1 to 60%, and the other four answers to 10%.
- On day 3, the consensus probabilities change such that Answer 1 is 15%, Answer 3 is 70%, and the other three answers are each 5%.
- The question resolves on day 2 with Answer 3 as the correct outcome.
The Brier Score for day 1 is:
(0.2 - 0)^2 + (0.2 - 0)^2 + (0.2 - 1)^2 + (0.2 - 0)^2 + (0.2 - 0)^2 = 0.8
The Brier Score for day 2:
(0.6 - 0)^2 + (0.1 - 0)^2 + (0.1 - 1)^2 + (0.1 - 0)^2 + (0.1 - 0)^2 = 1.2
The Brier score for day 3:
(0.15 - 0)^2 + (0.05 - 0)^2 + (0.7 - 1)^2 + (0.05 - 0)^2 + (0.05 - 0)^2 = 0.12
Averaging these values gives an Accuracy score for the question of 0.707.
Is a single-value score sufficient for evaluating the accuracy of a question?
The average daily Brier score provides an accurate representation of how accurate the question was throughout its active run. Depending on how you use forecasts to make decisions, there may be other ways to evaluate accuracy. We can look at the time-period component scores to determine how accurate a question was at a specific point in time. For example, it may be useful to compare question accuracy by looking at the forecast at a specific time before the outcome was know. For example, examining the score 1 week before the outcome was known may be useful in understanding how accurate a forecast was while there was still time to act on it.
Ordinal or Ordered Question Scoring
We have an optional ability to use a modified scoring strategy for questions whose answers are ordered, and we would like to consider forecasts in answers closer in order to the correct answer as being more accurate than those that are not. We refer to this strategy as ordinal scoring. Questions that forecast dates or numeric values may want to utilize ordinal scoring.
Instead of scoring answers individually, ordinal scoring works by creating groupings of answer before and after each intermediate point, and averaging the Brier score for each of those pairings. For a question with 3 answer, A, B, and C, we group them as (A,BC), and (AB,C). For (A,BC): we calculate the Brier score of A as we normally score do for an individual answer. We calculate the Brier score of BC by summing the forecasted probability of B and C against the outcome of B OR C, meaning that if either answer occurs, the outcome for BC is 1 (100%).
Ordinal Scoring Example
- An ordinal question is created with 5 possible answers (A, B, C, D, and E), and at the end of day 1, the consensus probability of each is 20%.
- By the end of day 2, a the consensus probabilities of the answers have changed such that answer A has a probability of 31.2% and the other answers are all 17.2%.
- The eventual outcome is C
To calculate the accuracy score, we average four calculations (one for each pairing): (A,BCDE), (AB,CDE), (ABC,DE), and (ABCD,E).
For Day 1, these values are:
(A,BCDE) = (0.2 - 0)^2 + (0.8 - 1)^2 = 0.08
(AB,CDE) = (0.4 - 0)^2 + (0.6 - 1)^2 = 0.32
(ABC,DE) = (0.6 - 1)^2 + (0.4 - 0)^2 = 0.32
(ABCD,E) = (0.8 - 1)^2 + (0.2 - 0)^2 = 0.08
The average of these values and score for day 1 is 0.2.
For Day 2, these values are:
(A,BCDE) = ( 0.312 - 0 )^2 + ( 0.688 - 1 )^2 = 0.196
(AB,CDE) = ( 0.484 - 0 )^2 + ( 0.516 - 1 )^2 = 0.47
(ABC,DE) = ( 0.656 - 1 )^2 + ( 0.344 - 0 )^2 = 0.236
(ABCD,E) = ( 0.828 - 1 )^2 + ( 0.172 - 0 )^2 = 0.059
The average of these values is 0.24.
Averaged across both days the score for this question is: 0.22. Compare this to the same question as scored without using ordinal scoring in Example 2 above, and you’ll see that this score is much better. This reflects how ordinal scoring rewards forecasts that are close to the correct outcome.
It is important to note that ordinal scoring will result is better scores than regular scoring. You should take this into account when attempting to compare the accuracy of questions scored using different strategies.
Site-wide and Challenge Accuracy Scores
Challenges receive a score by finding either the mean or median score of the questions within that challenge. Whether to use mean or median is a configurable setting. Similarly, a side-wide score is calculated using either the mean or median of all questions on the site. See the Scoring Strategy section for more detail about configurable settings.
Accuracy Scoring for Users
Forecasters within the application receive accuracy scores in much the same way as questions do. A forecaster’s score is based upon the forecasts they provided, rather than the consensus forecast. Scores are based upon probability estimates, provided either as a supplementation to a prediction market trade where they are asked to provide a probability estimate for only the answer they are trading in, or on an opinion pool type question where they are required to provide probability estimates for all answers to the question.
Relative Accuracy Scores
Evaluating user accuracy relative to other users has several advantages over simply examining their individual forecasts.
Some questions are more difficult than others. If a user participates in a difficult question, they will be at a disadvantage as compared to someone who participates in an easier question. This will discourage users from making forecasts in questions where the probabilities are not near the extremes. For instance, forecasting that there is a 50% probability that an event will occur will never result in a “good” Brier score. If a user strongly believes that outcome is uncertain, they would not want to make a forecast even if it would help correct the consensus forecast. Additionally, forecasters are incented to wait until there is more information available and the outcome
In pure prediction market, where the primary incentive is the accumulation of cash or points, getting into a position early has strong advantages.
In a pure opinion pool, where users forecast probabilities out outcomes and are evaluated solely on those forecasts, relative accuracy scoring provides a strong incentive to make forecasts any time where they believe their forecast is better than the consensus.
In a hybrid prediction market, where in addition to the market aspects users are required to provide probability estimates, and they are evaluated both by accumulation of cash and by the accuracy of their forecasts, relative scoring provides the forecasters with similar incentives for their prediction market trades and their probability estimates: any time your forecast differs from the consensus, you should make a forecast.
Relative Score Calculation
Relative scores are calculated by finding the difference between your score and the median score for all forecasters during a given period. If your Brier score for a period was 0.5, and the median Brier score was 0.7, your relative score for that period is -0.2. A negative relative score is good, as it indicates your Brier was lower (better) than the median.
The relative score for the question is calculated by: First, finding the difference between the forecaster’s average Brier score for the periods they forecasted and the average of the median Brier score for the periods they forecasted. Then multiplying that by the percent of the total periods/time that the forecaster participated in. If a forecasters average Brier score was 0.26, and the median Brier score during the time they were scored was 0.2, and they make their first forecast ⅓ into the time the question was active, then their relative score is: ⅔ of (0.26 - 0.2), or 0.04.
Relative Score Simplified Example
|
Day1 |
Day 2 |
Day 3 |
|
|
Forecaster’s Score |
No Forecast |
0.29 |
0.23 |
|
Median Score |
0.5 |
0.25 |
0.15 |
Percent of periods Forecaster received a score: 2 out of 3
Forecasters average score: (0.29 + 0.23) / 2 = 0.26
Average median score for periods in which Forecasters was scored: (0.25 + 0.15) / 2 = 0.20
Forecaster relative score: ((0.26 - 0.20) x 2) / 3 = 0.04
Scoring and Behavior Incentives
|
Opinion Pool |
Prediction Market |
Hybrid Prediction Market |
|
|
Cash Balance |
N/A |
Make forecasts when: 1) You believe the current price is farther from the eventual outcome than it should be: e.g. If probability is at 20%, but you believe there is a 30% chance, then you should buy. 2) You believe you can predict the behavior of other forecasters, regardless of the eventual outcome: e.g. The probability is 20%, and you have no sense of the eventual outcome but you believe positive news will eventually cause other forecasters to bring the probability to 50%, you should buy now and sell when the price goes up. |
Complemented well by Relative Accuracy Scoring. Incentive #2 (in the cell to the left) does not necessarily contribute to the overall accuracy of the question, and rewarding that behavior can be counter productive. When the goal is to produce accurate consensus probabilities, forecasters should predict based upon outcomes. |
|
Accuracy Score |
You should only make forecasts when you feel strongly that the outcome is clear. |
N/A |
Can discourage forecasts that make the question better, and be an incentive against correcting questions that have strayed too close to a potential outcome back towards the center. This requires that we collect probability estimates for each answer within a stock. |
|
Relative Accuracy Score |
You should make forecasts whenever you believe you have information, regardless of the uncertainty of the outcome. |
N/A |
This complements evaluating forecasters based on Cash Balance. It reinforces forecasts made when you believe you have information about the eventual outcome, and discourages forecasts made based on expected trader behavior rather than knowledge about the outcome. This approach does not require forecasters to provide a probability estimate for each answer, which fits well with prediction market trading. |
Leaderboards
There are variety of leaderboards designed to identify and reward the best forecasters while incentivizing all users to have optimal forecasting behaviour. There are two types of metrics which are indicative of forecaster performance and can be used to construct leaderboards:
- Accuracy Score based leaderboards based upon probability estimates provided by forecasters.
- Prediction Market earnings based leaderboards based upon cash/points accumulated through trades.
Site-wide and Challenge
We produce leaderboards at both the challenge level and across the entire site. Challenge-level leaderboards allow users to be competitive in the areas they have expertise while making it easy to identify who the experts in each challenge are.
Leaderboard Eligibility
There is no minimum level of forecasting activity required to be eligible for the leaderboard or to remain on the leaderboard. There are three reasons for this:
- Leaderboards are a primary source of engagement and drive good forecasting behavior. Indeed, when a site or a Challenge is new and very few questions have resolved, leaderboards will be very dynamic and not necessarily indicative of who the best forecasters are. It is true that lucky forecasters may appear atop the leaderboard for a short time, however as more questions are resolved, good forecasters will make their way to the top.
- The leaderboards are designed in such a way that earning and maintaining a spot on them requires both accuracy and effort. If a user is able to gain a spot on the leaderboard and then proceed to maintain that despite a significant and prolonged drop in activity, that is a sign that the site has an overall unhealthy level of activity.
- Challenge-specific leaderboards provide newcomers with an opportunity for recognition.
Scoring Strategies
Overview
When calculating a score there are several different strategies that can be used to score possible scenarios. Often, there is no right or wrong strategy, and the decision of which one is best to use is unclear. Examples of scenarios that these strategies cover are: Should users receive a score in a question for the time before they made their first forecast? Should we continue to score possible answers after the possibility they they could occur is eliminated? If so, for how long and what probability should the score be based off of?
We have implemented several of these strategies as configurable settings, and their descriptions are below. The default settings are indicated, and were chosen based on what we have found to be most indicative of accurate forecasts while being understandable to the average forecaster. You should choose settings based on the sophistication of your forecasters and the behaviors you want to incentivize and reward.
Each of these settings may be configured independently, meaning there many different combinations of settings. It is possible to have multiple scoring strategy configured simultaneously, which will allow simultaneous direct comparison of scores calculated with any combination of settings. A site will always have a single default scoring strategy, which leaderboards and scores displayed to users will be based off of.
Settings available in Cultivate Forecasts
Use Relative Brier Scoring
-
Do you want users to utilize relative Brier scoring (enabled by
default)? With Relative scoring, the score a user receives is their score
relative to the other users who participate in the same questions. User's
are rewarded for making predictions that improve the consensus forecast.
Without relative scoring, a user is scored based on how close their forecasts
are to the eventual question outcome, regardless of how well other
forecasters perform. Users who make most of their forecasts in 'easy'
questions, or those who wait until more information is available, will have
an advantage of those who forecast in more challenging questions or earlier
in a questions life
Sampling Frequency
- Daily (default) - Calculate one score every day for each possible outcome within a question. For scoring a question, use the latest consensus probability or price before the time specified by the sample cutoff start time. When scoring a user, use their most recent forecast before the sample cutoff start time. To arrive at a score for the whole question, we average these daily component scores.
Sample Cutoff Start Time
The time of day that marks the start of a daily sample for scoring. You provide an offset from midnight and a time zone.- Time Zone (default is UTC)
- Offset from Midnight 00:00 (default is 0)
Brier Score Display Format
- Brier - The unformatted Brier score, a value between 0 and 2, where 0 is a perfect forecast and 2 results from assigning no probability to the eventual outcome.
- Inkling Accuracy Score - A transformation of the Brier that produces values between 50 and 100. 100 is the result of a perfect forecasts (a 0.0 Brier score) and 50 is the result of of the worst possible forecast (a 2.0 Brier score). Assigning equal probabilities to all outcomes results in a score of 75. The format is akin to a grading scale (A, B, C, D, F), where 90-100 would an A or excellent, 80-90 would be a B or good, 70-80 would be a C or mediocre, etc. The calculation for this format is: (200 - (Brier x 50)) / 2
- SciCast Simple Accuracy - Again, this is a simple transformation of the Brier that was used in the SciCast prediction market. It produces values between -100 and 100, where 0 is assigning equal probabilities to all outcomes. The calculation for this format is: (200 - (Brier x 200)) / 2
- [0-100] Accuracy Scores - Similar to Inkling and SciCast, however the scores will range from 0 (bad) to 100 (good). The calculation for this is: (200 - (Brier x 100)) / 2
-
Accuracy Scores for Relative Scoring (default) -
This display format is only useful for representing relative brier scores.
Forecasters can win up to 100 points, and lose up to 100 points, per
question. The average forecaster will earn 0 points. If a forecast is better
than average, it will earn points. If it is worse than average, it will lose
points. The maximum amount you can win or lose per question depends on how
well the average forecaster performed. The calculation for this is:
(-Brier x 200) / 4
Site Averaging Strategy
When calculating the site’s overall score or a user’s overall score, this setting determines how to “average” the question scores.
- Mean (default)
- Median
Challenge Averaging Strategy
When calculating the score for a Challenge or a user’s score within a Challenge based off of the scores of questions within that challenge, this setting determines how to “average” the Challenge’s question scores.
- Mean (default)
- Median
Pre-Prediction Scoring Strategy
Determines how to score the time/periods before a prediction has been made. For scoring question accuracy, this is before any forecast has been made on an outcome. For scoring a user within a question, this is before the user has made their first forecast on an outcome.
- Users are not scored until they have made a forecast (default) - The periods before any predictions are made are not factored into the score. For users, this means they don't receive a score until their first forecast. For an answer, this means it won't receive a score until someone makes a forecast.
- Users receive scores based upon the consensus forecast the time before their first forecast - The periods, or time, before any predictions are made receive a score based off the consensus probability/price for those periods. For a user, this means they'll receive a score based off the answers consensus probability or price. For an answer, this means it will use the outcomes initial probability/price.
- Users receive scores based upon the initial/starting probability - Users receive scores based upon the initial/starting probability of the answer prior to their first forecast.
- Users receive scores based upon a uniform distribution of probability - Users receive scores based upon a uniform distribution of probability amongst active answer for the time prior to their first forecast.
Perform Scoring Post-Resolution Strategy
This setting determines when to stop scoring an outcome that has been resolved.
- All answers scored until question resolves - All answers in a question are scored up until the question resolved. This means that if an answer resolves before the question, it will continue to be scored up until the question as a whole resolves. The scoring of these resolved answer is determined by the Post-Resolution Answer Strategy
- Answers are scored up to and including the period in which they are resolved (default)
- Answers are scored up until the period in which it was resolved. They do not receive a score during the resolution period
Post Resolution Scoring Strategy
This setting determines how to score answers after their outcome is known. This setting is considered only if the Perform Scoring Post-Resolution Strategy is Score before resolution period.
- Use resolution value (default) - When scoring after the outcome was known, or the period in which the outcome was known, use the outcome (0% or 100%) to calculate the score.
- Use last forecast - When scoring after the outcome was known, or the period in which the outcome was known, use the last consensus forecast or price for questions or the user’s last forecast for users.
- They should not be scored
- They should not be scored, including the scoring period in which they resolved
